Инциденты
Начиная с версии 201
Модуль Инциденты доступен начиная с версии 201. Он автоматически группирует связанные алерты в инциденты, ведёт их по этапам жизненного цикла и помогает с поиском первопричины с помощью ИИ.На этой странице:
- Что такое инцидент
- Список инцидентов
- Карточка инцидента
- Этапы инцидента
- ИИ-сводка
- ИИ-расследование первопричины
- Затронутые ресурсы, связанные алерты и граф распространения
- Таймлайн и хронология
- Объединение инцидентов
- Ответственный
- Настройки Инцидентов
Когда в инфраструктуре что-то ломается, обычно срабатывает не один алерт, а сразу несколько: падение пода тянет за собой ошибки зависимых сервисов, превышение SLO, рост задержек и так далее. Если смотреть на это как на поток отдельных алертов, легко утонуть в шуме и упустить общую картину.
Модуль Инциденты решает эту задачу: платформа автоматически коррелирует связанные алерты и объединяет их в один инцидент. Дежурный работает не с десятками одинаковых уведомлений, а с одной сущностью, у которой есть первопричина, охват, ответственный и история. Раздел доступен в главном меню: Инциденты и Алерты > Инциденты. Он живёт в одном разделе с алертами — инциденты строятся именно из сработавших алертов.
Что такое инцидент
Инцидент — это группа связанных алертов, объединённых платформой по общему признаку (например, по одному и тому же ресурсу или совпадающим лейблам). Корреляция выполняется автоматически и в реальном времени: как только появляются новые алерты, относящиеся к уже открытому инциденту, они присоединяются к нему, а не порождают новые сущности.
У каждого инцидента есть:
| Атрибут | Описание |
|---|---|
| Критичность | Наивысшая критичность среди входящих алертов: Критический, Высокий, Средний или Низкий. |
| Этап | Текущая фаза жизненного цикла: Обнаружен, Диагностика, Устранение, Закрыт (см. Этапы инцидента). |
| Охват | Количество связанных алертов и затронутых ресурсов. |
| Влияние | Оценка масштаба (например, Локальное влияние) с числом затронутых ресурсов. |
| Ответственный | Пользователь, назначенный на работу с инцидентом. |
| Возраст | Время с момента создания и время последнего обновления. |
Благодаря корреляции десятки однотипных алертов (например, по нескольким подам одного неймспейса) сворачиваются в один инцидент, что резко снижает шум и ускоряет реагирование.
Список инцидентов
Раздел Инциденты > Список инцидентов показывает активные и недавние инциденты по доступным вам сервисам. Список обновляется автоматически.
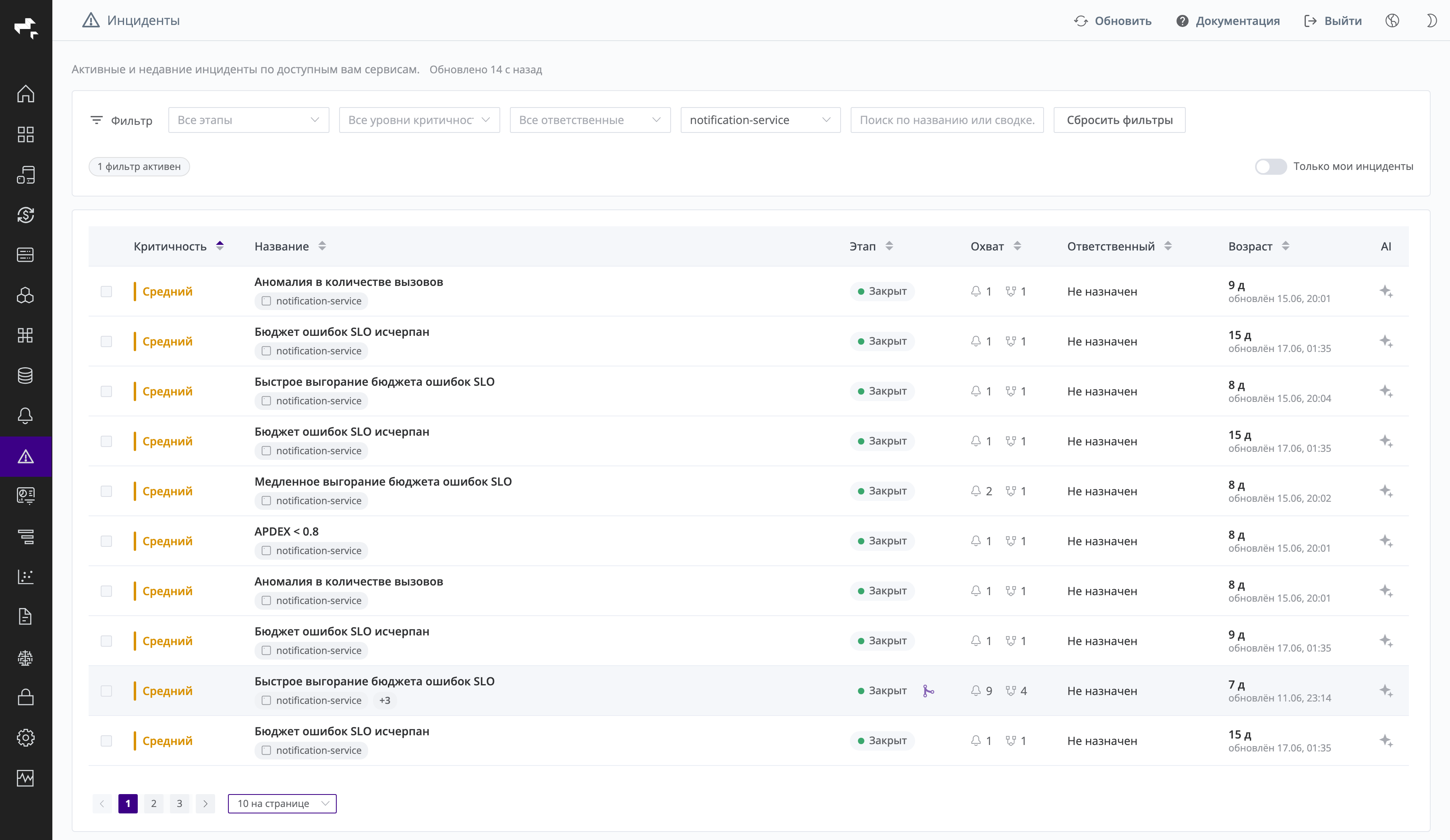 Скриншот: список инцидентов, отфильтрованный по сервису и отсортированный по критичности.
Скриншот: список инцидентов, отфильтрованный по сервису и отсортированный по критичности.
Колонки таблицы:
| Колонка | Значение |
|---|---|
| Критичность | Наивысшая критичность инцидента. По столбцу можно сортировать. |
| Название | Заголовок инцидента и сервис, к которому он относится. |
| Этап | Текущая фаза жизненного цикла. |
| Охват | Число связанных алертов и затронутых ресурсов. |
| Ответственный | Назначенный пользователь (или Не назначен). |
| Возраст | Длительность инцидента и время последнего обновления. |
| AI | Признак наличия ИИ-сводки и ИИ-расследования. |
Над таблицей расположена панель фильтров. Доступна фильтрация по этапу, уровню критичности, ответственному и сервису, а также полнотекстовый поиск по названию или сводке. Счётчик N фильтр активен показывает, сколько фильтров применено; кнопка Сбросить фильтры снимает их все. Переключатель Только мои инциденты оставляет в списке инциденты, назначенные на текущего пользователя.
Список разбит на страницы на стороне сервера; размер страницы выбирается внизу (10 / 20 / 50 / 100 на странице). Клик по строке открывает карточку инцидента.
Карточка инцидента
Карточка инцидента — это рабочее место для разбора проблемы. В шапке отображаются критичность, влияние с числом затронутых ресурсов, возраст, время создания и последнего обновления, а также заголовок инцидента (его можно переименовать) и кнопка Объединить с….
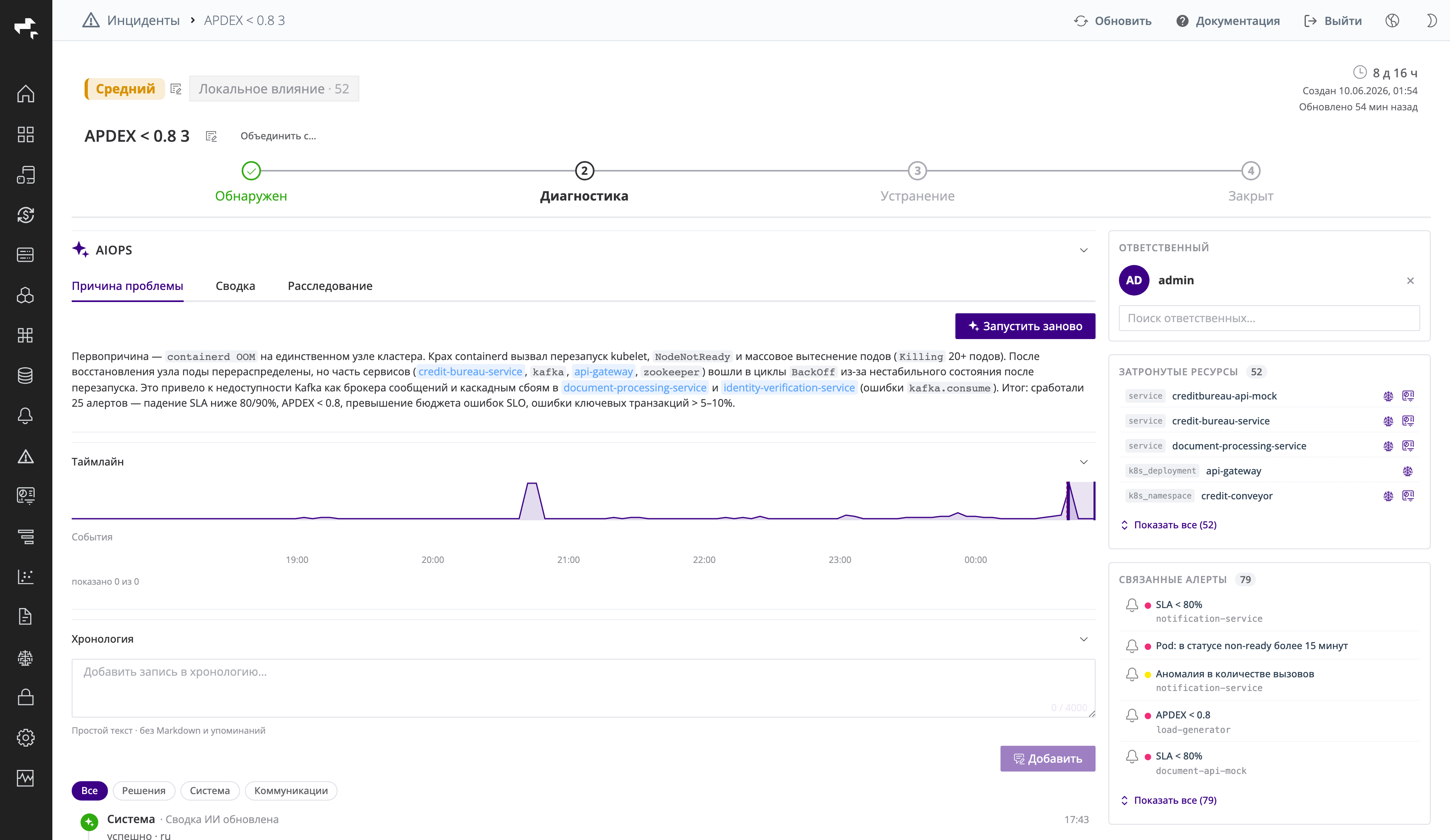 Скриншот: карточка инцидента с первопричиной, степпером этапов и правой колонкой (ответственный, затронутые ресурсы, связанные алерты).
Скриншот: карточка инцидента с первопричиной, степпером этапов и правой колонкой (ответственный, затронутые ресурсы, связанные алерты).
Карточка состоит из трёх логических зон:
- Степпер этапов вверху — текущая фаза жизненного цикла и переход между этапами.
- Панель AIOPS в центре — вкладки
Причина проблемы,СводкаиРасследование, а также таймлайн и хронология. - Правая колонка — ответственный, затронутые ресурсы и связанные алерты.
Этапы инцидента
Инцидент проходит четыре этапа жизненного цикла в соответствии с практиками ITIL:
- Обнаружен — инцидент только что создан корреляцией алертов.
- Диагностика — идёт поиск причины.
- Устранение — причина найдена, выполняются восстановительные действия.
- Закрыт — проблема решена.
Текущий этап показан степпером в карточке и колонкой Этап в списке. Переход между этапами выполняется вручную; часть переходов (например, автоматическое закрытие после разрешения всех алертов) платформа выполняет сама. Названия и порядок этапов можно изменить — см. Настройки Инцидентов.
ИИ-сводка
Вкладка Сводка панели AIOPS содержит автоматически сгенерированное текстовое описание инцидента: что произошло, когда, какие сервисы затронуты и как развивалась ситуация. Сводка формируется на русском и английском языках и обновляется по мере развития инцидента.
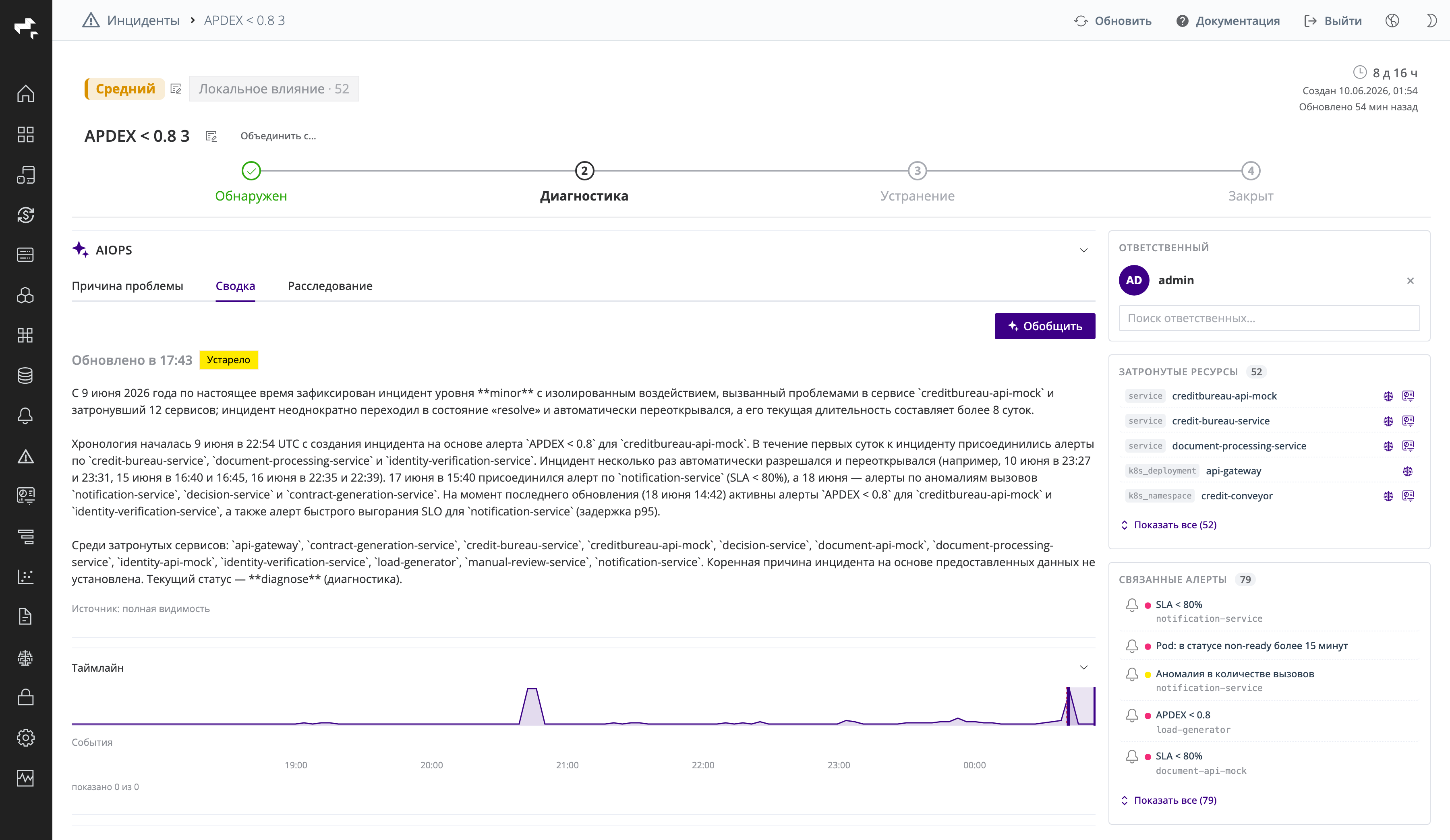 Скриншот: ИИ-сводка инцидента с отметкой времени последнего обновления.
Скриншот: ИИ-сводка инцидента с отметкой времени последнего обновления.
Рядом с заголовком показано время последнего обновления сводки; если с тех пор инцидент изменился, появляется отметка Устарело. Кнопка Обобщить запускает повторную генерацию сводки с учётом актуальных данных.
ИИ-расследование первопричины
Вкладка Расследование запускает ИИ-анализ первопричины инцидента. В отличие от сводки (которая описывает что произошло), расследование отвечает на вопрос почему это произошло.
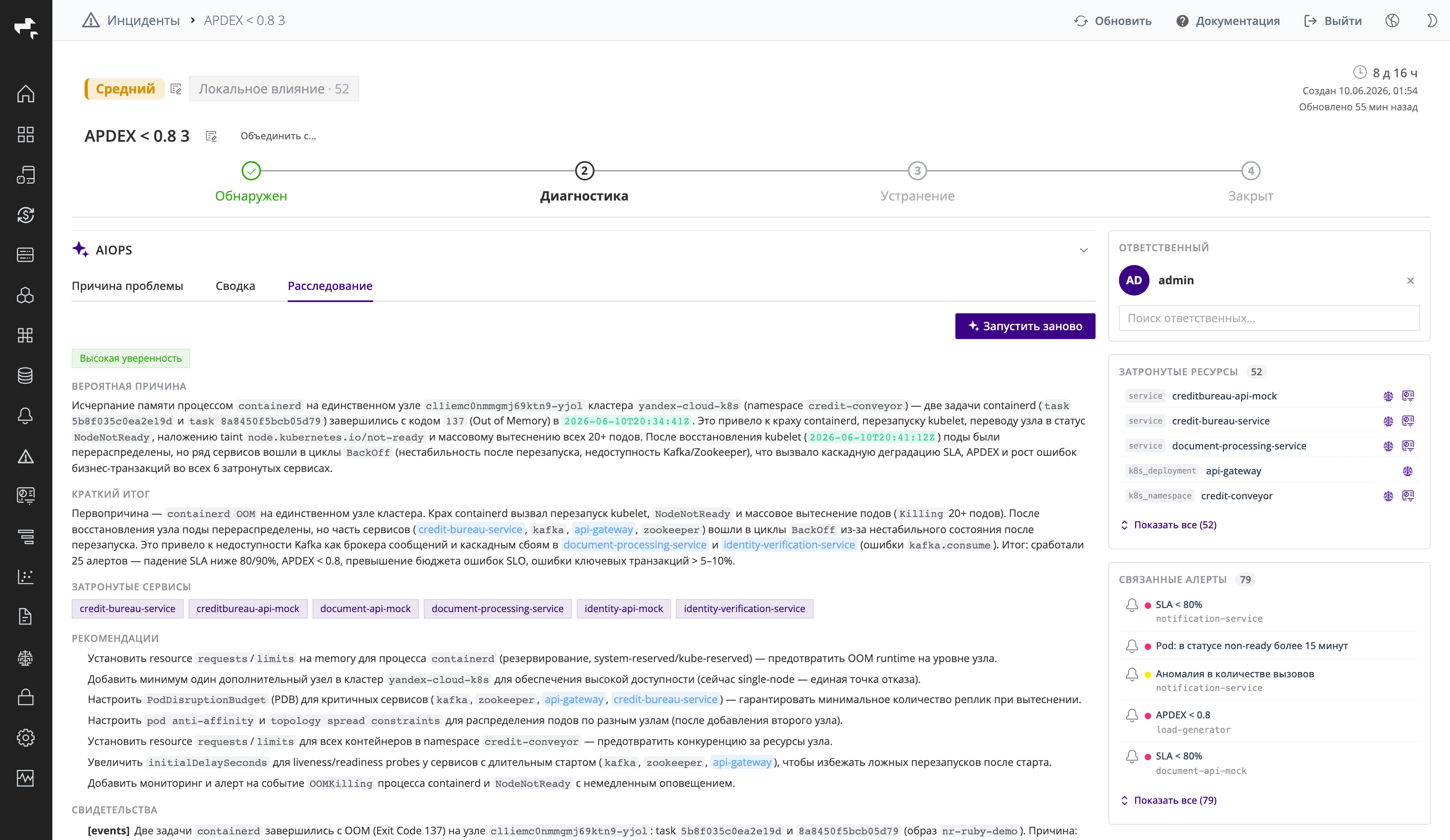 Скриншот: ИИ-расследование с уровнем уверенности, цепочкой первопричины, затронутыми сервисами и рекомендациями.
Скриншот: ИИ-расследование с уровнем уверенности, цепочкой первопричины, затронутыми сервисами и рекомендациями.
Результат расследования включает:
- Уровень уверенности (например,
Высокая уверенность); - Первопричину и цепочку развития проблемы — как первичный сбой привёл к каскаду вторичных;
- Затронутые сервисы;
- Рекомендации по устранению.
Краткая выжимка первопричины дублируется на вкладке Причина проблемы. Запустить расследование можно кнопкой Расследовать; повторный анализ — кнопкой Запустить заново.
Затронутые ресурсы, связанные алерты и граф распространения
Правая колонка карточки показывает затронутые ресурсы (с типом ресурса — сервис, под Kubernetes, неймспейс, деплоймент и т. д.) и связанные алерты. По кнопке Показать все (N) раскрывается полный список.
Внизу карточки доступны развёрнутые блоки:
- Затронутые ресурсы (полный список) — все ресурсы инцидента.
- Связанные алерты (полная таблица) — все алерты со столбцами: состояние, критичность, описание, объект (
Где), время начала и конца, длительность и переход к контексту. - Граф распространения — визуализация «радиуса поражения»: центральный узел инцидента и связанные с ним ресурсы.
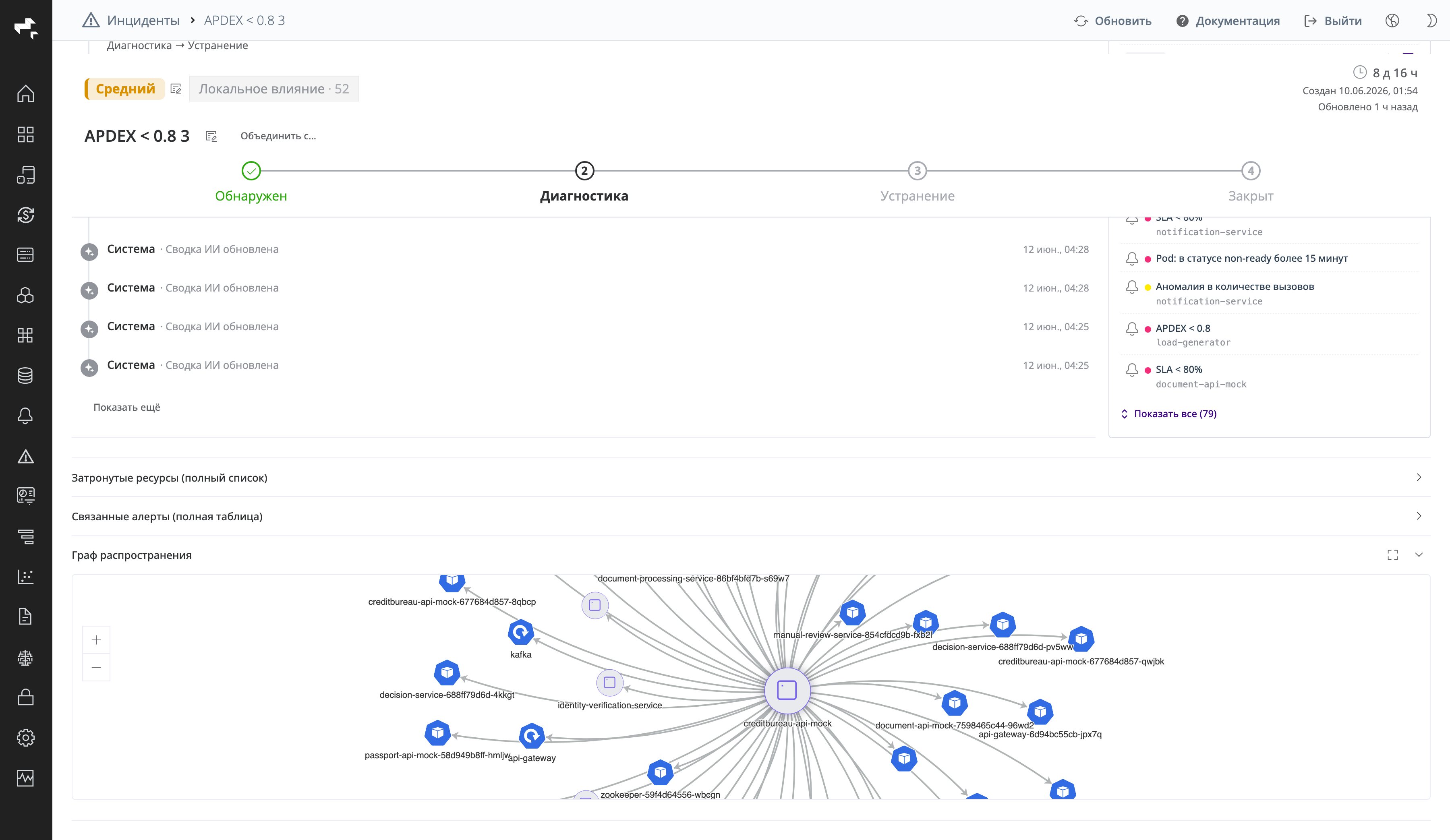 Скриншот: граф распространения — центральный узел инцидента и затронутые ресурсы.
Скриншот: граф распространения — центральный узел инцидента и затронутые ресурсы.
Граф помогает быстро оценить масштаб инцидента и увидеть, какие компоненты инфраструктуры оказались вовлечены.
Таймлайн и хронология
Таймлайн показывает события инцидента на шкале времени — наглядную «ось» развития ситуации.
Хронология — это журнал инцидента с фильтрами Все, Решения, Система, Коммуникации. В неё попадают как системные записи (создание инцидента с указанием признака корреляции, объединение инцидентов, обновление ИИ-сводки), так и заметки пользователей. Добавить собственную заметку можно в поле ввода (простой текст, без Markdown).
Системная запись о создании инцидента содержит признак корреляции — например, same resource: k8s_pod=<кластер>|<неймспейс>|<под> — то есть основание, по которому алерты были объединены.
Объединение инцидентов
Если платформа определяет, что несколько инцидентов относятся к одной проблеме, она объединяет их: алерты и ресурсы переносятся в один инцидент, а в его хронологии появляются записи вида в этот инцидент влит инцидент #<id>. Объединение можно выполнить и вручную — кнопкой Объединить с… в шапке карточки. Это удобно, когда фрагменты одной аварии изначально попали в разные инциденты.
Ответственный
В правой колонке карточки назначается ответственный за инцидент. Можно назначить себя кнопкой Назначить меня → или выбрать пользователя через поиск. Назначение отражается в списке (колонка Ответственный), а переключатель Только мои инциденты помогает дежурному видеть только свои инциденты.
Настройки Инцидентов
Раздел Инциденты и Алерты > Настройки Инцидентов позволяет переименовать и переупорядочить четыре этапа инцидента, отображаемые в интерфейсе.
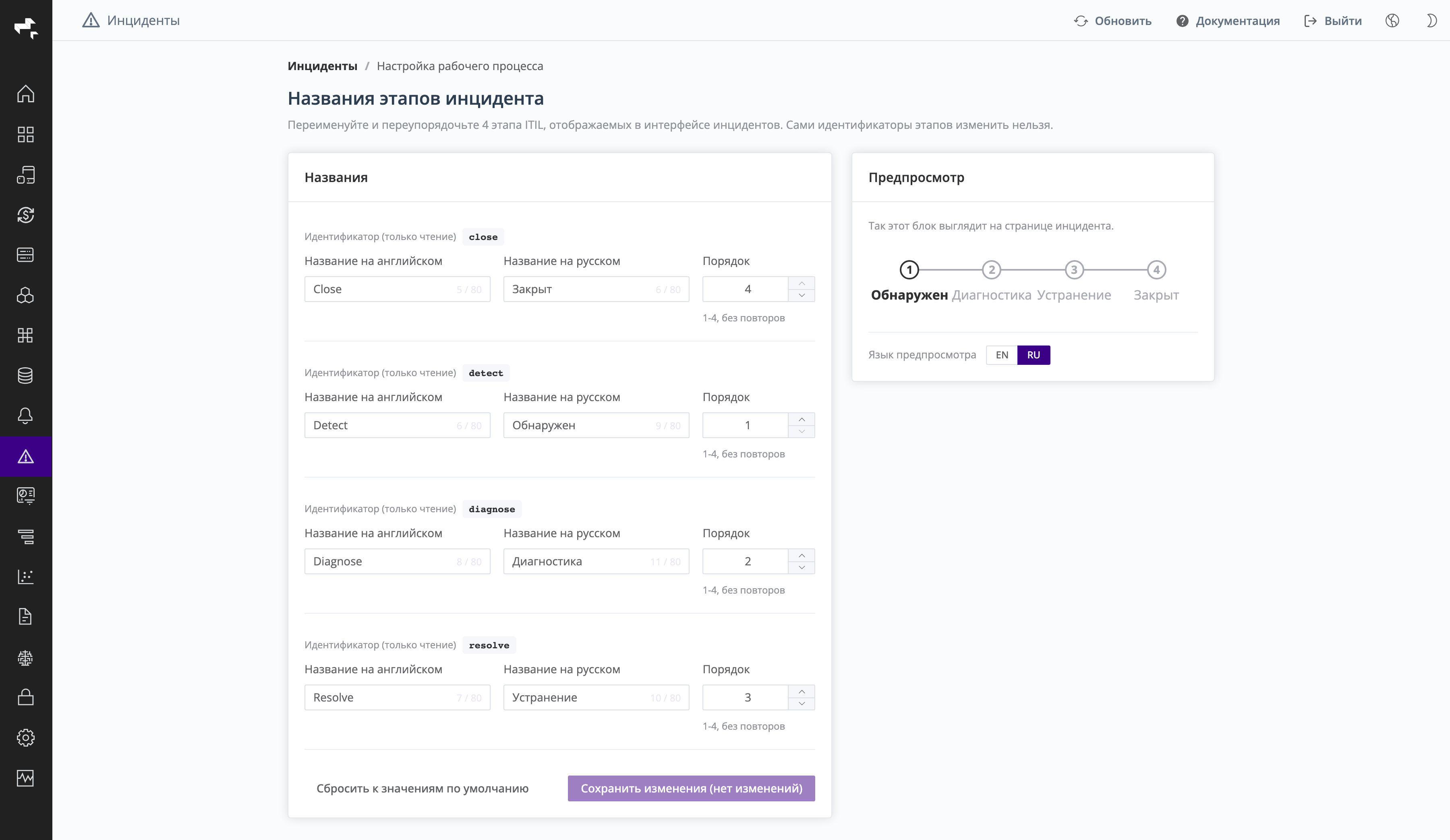 Скриншот: настройка названий и порядка этапов инцидента с предпросмотром.
Скриншот: настройка названий и порядка этапов инцидента с предпросмотром.
Для каждого этапа задаются:
- Идентификатор (
detect,diagnose,resolve,close) — только для чтения, изменить его нельзя; - Название на английском и Название на русском (до 80 символов);
- Порядок (значения 1–4, без повторов).
Блок Предпросмотр показывает, как степпер будет выглядеть на странице инцидента, с переключением языка EN / RU. Кнопка Сбросить к значениям по умолчанию возвращает стандартные названия и порядок, Сохранить изменения — применяет настройки.