Выявление аномалий
На этой странице:
- Что это такое
- Какие метрики профилируются
- Встроенные правила выявления аномалий
- Как добавить метрики в профилирование
- Дополнительные параметры
- Что дальше
Что это такое
Выявление аномалий — механизм Proto Observability Platform, который с помощью машинного обучения (ML) автоматически строит базовую линию (ожидаемый диапазон значений, baseline) для ключевых показателей каждого сервиса и ключевой транзакции. Базовая линия учитывает суточную и недельную сезонность и постоянно переобучается на свежих данных, поэтому не требует ручной настройки порогов — она подстраивается под нормальное поведение каждого сервиса.
Аномалией считается выход фактического значения за верхнюю границу ожидаемого диапазона. Базовую линию рассчитывает сервис proto-metric-analyzer.
 Скриншот: базовая линия (серая область — ожидаемый диапазон) и фактические значения (линия) для вызовов, ошибок и времени отклика.
Скриншот: базовая линия (серая область — ожидаемый диапазон) и фактические значения (линия) для вызовов, ошибок и времени отклика.
Для каждой профилируемой метрики платформа публикует сопутствующий набор метрик базовой линии с суффиксом _prophet и лейблом value_type: yhat — прогноз, yhat_lower и yhat_upper — нижняя и верхняя границы ожидаемого диапазона. На этих метриках строятся встроенные правила алертинга. Подробнее о метриках базовой линии — Метрики и выражения для правил.
Какие метрики профилируются
Из коробки базовая линия рассчитывается для следующих метрик:
| Категория | Метрика | Показатель |
|---|---|---|
| Сервисы | services_calls | количество вызовов |
| Сервисы | services_callduration | время отклика |
| Сервисы | services_errorcallsperc | доля вызовов с ошибками |
| Ключевые транзакции | calls_keybusinesstransactioncount | количество вызовов |
| Ключевые транзакции | calls_keybusinesstransactionduration | время отклика |
| Ключевые транзакции | calls_keybusinesstransactionerrorperc | доля вызовов с ошибками |
| Хосты | system_cpu_idle | простой CPU |
| Хосты | system_mem_usable | доступная память |
Для каждой из этих метрик автоматически публикуется набор метрик базовой линии <метрика>_prophet. Встроенные правила алертинга есть для метрик сервисов и ключевых транзакций (см. ниже). Для системных метрик базовая линия публикуется, но встроенного правила нет — при необходимости создайте собственное.
Встроенные правила выявления аномалий
Из коробки доступны правила алертинга в группе ANOMALY (критичность WARNING, срабатывание при выполнении условия в течение 7 минут). Каждое правило сравнивает фактическое значение метрики с верхней границей её базовой линии:
| Правило | Метрика | Когда срабатывает |
|---|---|---|
| Аномалия в количестве вызовов | services_calls | фактическое число вызовов выше ожидаемого диапазона |
| Аномалия во времени отклика | services_callduration | время отклика выше ожидаемого |
| Аномалия в количестве ошибок | services_errorcallsperc | доля ошибок выше ожидаемой |
| Аномалия в количестве вызовов ключевой транзакции | calls_keybusinesstransactioncount | то же для ключевой транзакции |
| Аномалия во времени отклика ключевой транзакции | calls_keybusinesstransactionduration | то же для ключевой транзакции |
| Аномалия в проценте ошибок ключевой транзакции | calls_keybusinesstransactionerrorperc | то же для ключевой транзакции |
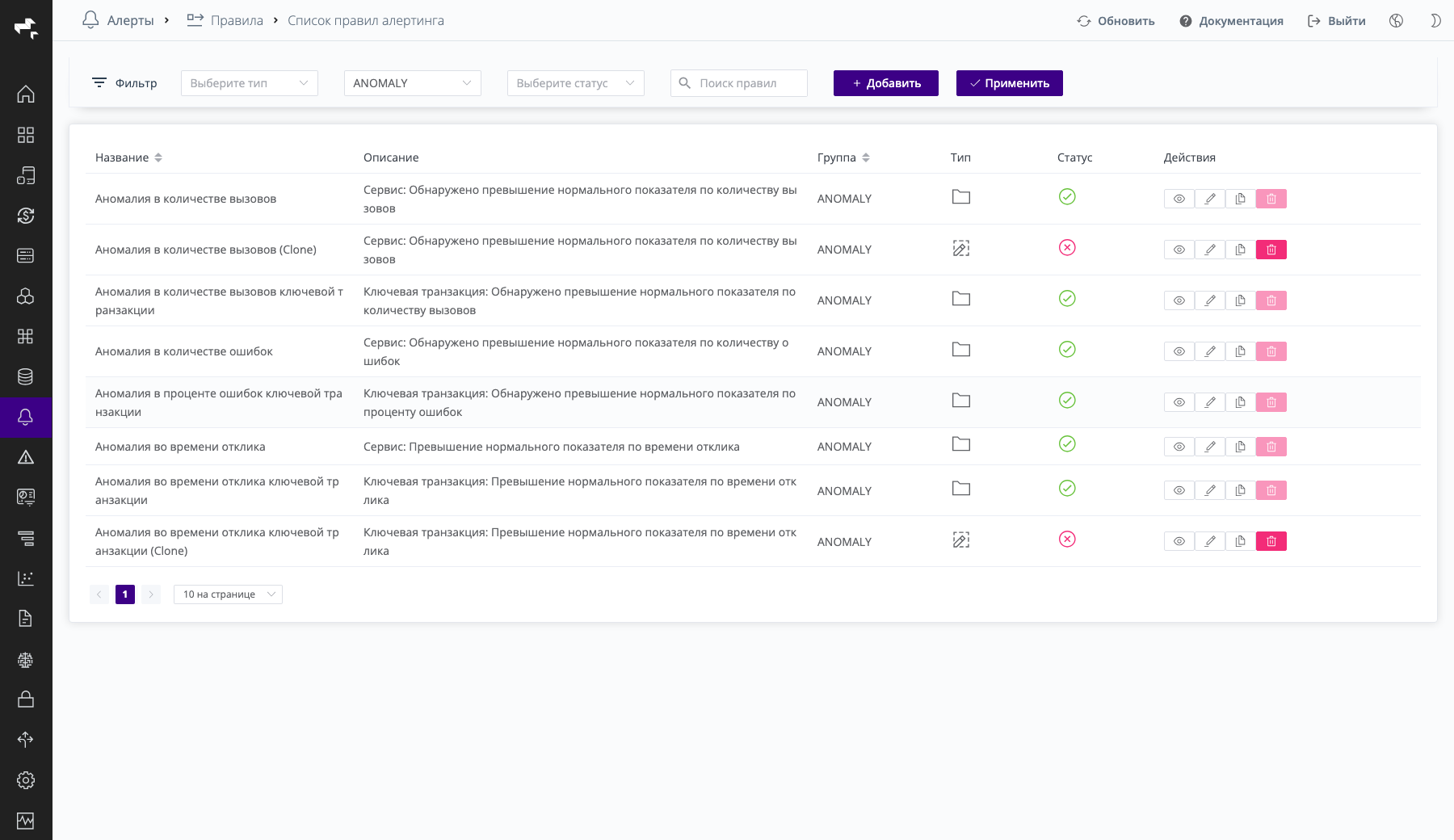 Скриншот: список правил, отфильтрованный по группе
Скриншот: список правил, отфильтрованный по группе ANOMALY.
Все правила односторонние — срабатывают только при превышении верхней границы (value_type="yhat_upper") и только при наличии трафика. Дополнительные условия по трафику подавляют ложные срабатывания при простое сервиса и в период первичного обучения модели. Схема выражения:
sum(services_calls) by (service, service_id, service_group)
> sum(services_calls_prophet{value_type="yhat_upper"}) by (service, service_id, service_group)
and avg(services_calls) by (service, service_id, service_group) > 0
Эти правила встроенные: их нельзя редактировать или удалить, но можно отключить или создать копию и настроить уже копию — см. Настройка оповещений → Работа с правилами.
Как добавить метрики в профилирование
Список профилируемых метрик задаётся в конфигурации сервиса proto-metric-analyzer через переменные окружения — изменение кода не требуется. Доступны две переменные:
POBP_ADDITIONAL_METRICS_LIST— рекомендуемый способ расширения. Список метрик через;, который добавляется к стандартному набору (с дедупликацией).POBP_METRICS_LIST— полностью заменяет стандартный набор (тогда нужно перечислить и стандартные метрики, и новые).
В элементе списка можно указать селектор лейблов, например up{app="payments"} — каждая подходящая серия профилируется отдельно.
Пример для docker-compose (добавить APDEX сервисов и свою метрику):
services:
proto-metric-analyzer:
environment:
POBP_ADDITIONAL_METRICS_LIST: "services_apdex;my_custom_metric"
После применения для новой метрики автоматически появятся метрики базовой линии <метрика>_prophet.
Базовая линия — это не алерт
Профилирование метрики не создаёт правило алертинга автоматически. Чтобы получать оповещения по новой метрике, добавьте собственное правило (см. Создание правила), сравнив метрику с её верхней границей:
sum(my_custom_metric) by (service, service_id)
> sum(my_custom_metric_prophet{value_type="yhat_upper"}) by (service, service_id)
Дополнительные параметры
Поведение профилирования настраивается переменными окружения сервиса proto-metric-analyzer:
| Переменная | По умолчанию | Назначение |
|---|---|---|
POBP_ROLLING_TRAINING_WINDOW_SIZE | 7d | объём истории для обучения модели |
POBP_RETRAINING_INTERVAL_MINUTES | 120 | как часто переобучается модель |
POBP_Z_THRESHOLD | 3.0 | чувствительность: ширина доверительного интервала (меньше — чувствительнее) |
POBP_DIRECTION_DEFAULT | both | направление аномалии: up / down / both |
Версия
ПараметрыPOBP_Z_THRESHOLD и POBP_DIRECTION_DEFAULT доступны начиная с версии 201.Что дальше
- Алертинг в Proto Observability Platform — обзор модуля алертинга.
- Настройка оповещений — создание каналов, политик и правил, работа с правилами.
- Метрики и выражения для правил — метрики сервисов и метрики базовой линии
_prophet.