Быстрый старт: первое оповещение
Сквозной пример настройки оповещения в Proto Observability Platform: создать канал доставки, правило и политику маршрутизации и получить первое уведомление в Telegram.
На этой странице:
Модуль алертинга Proto Observability Platform отвечает за выявление проблем по телеметрии и доставку оповещений в нужные каналы. Эта страница даёт общее представление о модуле; пошаговые инструкции вынесены в отдельные руководства (см. В этом разделе).
Система оповещений складывается из трёх связанных сущностей, которые настраиваются в разделе главного меню Инциденты и Алерты:
| Сущность | Назначение |
|---|---|
| Правило алертинга | Условие на языке PromQL/MetricsQL, по которому генерируется алерт. |
| Политика оповещений | Маршрутизация: какие алерты в какой канал направлять (по лейблам). |
| Канал оповещения | Куда доставлять уведомления — email, Telegram, Webhook. |
Связка работает так: правило срабатывает по условию → политика сопоставляет лейблы алерта со своими матчерами и выбирает канал → канал доставляет уведомление получателю.
Пошаговая настройка каналов, политик и правил описана в руководстве Настройка оповещений. Справочник по метрикам и выражениям для правил — на странице Метрики и выражения для правил.
Новым пользователям стоит начать с раздела Быстрый старт — он за четыре шага проводит от создания канала до первого уведомления.
Пункт меню содержит подразделы:
| Подраздел | Назначение |
|---|---|
| Инциденты | Список и разбор инцидентов — подробнее |
| Активные Алерты | Стена срабатываний в реальном времени — подробнее |
| История Алертов | Журнал срабатываний с аналитикой и MTTR |
| Правила | Правила алертинга, встроенные и пользовательские |
| Каналы оповещения | Куда доставлять уведомления |
| Политики оповещения | Маршрутизация алертов по каналам |
| SLO | Цели уровня обслуживания — подробнее |
| Окна обслуживания | Регламентные работы и подавление оповещений (с версии 202) — подробнее |
| Настройки Инцидентов | Параметры корреляции и жизненного цикла инцидентов |
Из коробки доступно множество шаблонов правил алертинга, не требующих никакой дополнительной настройки. Список правил доступен в разделе Инциденты и Алерты > Правила:
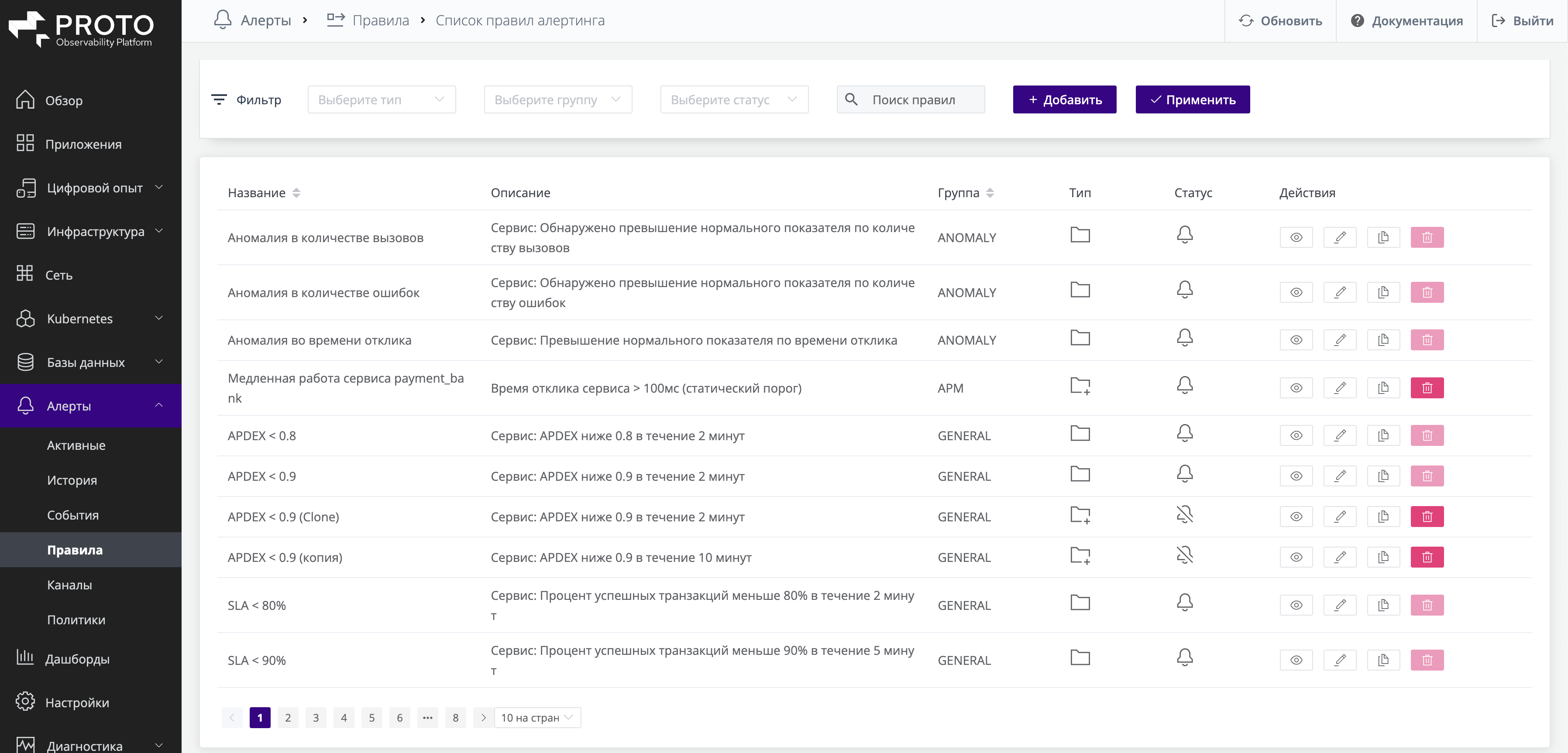
Встроенные правила алертинга не редактируются пользователями системы, но их можно отключить или сделать копию встроенного правила и уже в копии отредактировать все параметры. Встроенные правила периодически обновляются и дополняются вендором.
Чтобы добавить собственное правило, воспользуйтесь кнопкой Добавить — см. Настройка оповещений → Создание правила. О доступных метриках, синтаксисе выражений и аннотациях со ссылками на дашборды читайте на странице Метрики и выражения для правил.
Обычные пороговые правила проверяют условие, пока данные поступают: сравнение вроде «подключений больше 90 %» вычисляется по текущим значениям метрики. Если экспортёр, агент или сама цель выходят из строя, метрика перестаёт поступать — серия исчезает, и все пороговые правила по этому источнику молча замолкают вместе с ним. Источник фактически перестаёт наблюдаться, но ни одно правило об этом не сообщает: проблему замечают позже, по пустому графику.
Правила группы NO_DATA закрывают этот пробел — они срабатывают, когда источник, который слал метрики в течение последних суток, перестаёт их слать (данные не поступают дольше нескольких минут). Отсутствие данных — это тоже инцидент, и платформа сообщает о нём активно, а не оставляет дежурного наедине с пустым дашбордом.
Из коробки поддерживаются источники со стабильной идентичностью:
| Тип источника | Что считается «замолчавшим» |
|---|---|
| Хосты (ОС Linux) | хост перестал слать системные метрики |
| Сетевые устройства (SNMP) | устройство перестало отвечать на опрос |
| PostgreSQL | сервер СУБД перестал слать метрики |
| MySQL | сервер СУБД перестал слать метрики |
Особенности поведения:
Правила NO_DATA — встроенные: их не нужно настраивать, они появляются в разделе Инциденты и Алерты > Правила и, как и другие встроенные правила, могут быть отключены или скопированы для тонкой настройки.
Начиная с версии 200, при создании SLO (см. Управление SLO) платформа автоматически генерирует набор правил алертинга по скорости сжигания бюджета ошибок:
Метки и владелец из определения SLO автоматически прокидываются в алерты. Правила генерируются и обновляются сервисом proto-alert-rule-manager и появляются в общем списке правил алертинга.
Редактировать эти правила напрямую нельзя — для изменения условий измените параметры соответствующего SLO.
Платформа с помощью машинного обучения (ML) автоматически строит базовую линию (ожидаемый диапазон) для ключевых показателей каждого сервиса и ключевой транзакции — с учётом суточной и недельной сезонности и без ручной настройки порогов. При выходе значений за верхнюю границу базовой линии срабатывают встроенные правила группы ANOMALY.
Подробнее — какие метрики профилируются, какие правила доступны и как добавить собственные метрики в профилирование — см. Выявление аномалий.
Платформа автоматически коррелирует связанные алерты и объединяет их в инциденты: вместо потока однотипных уведомлений дежурный работает с одной сущностью, у которой есть первопричина, охват, ответственный, этапы жизненного цикла (ITIL) и история. Для инцидентов доступны ИИ-сводка, ИИ-расследование первопричины и граф распространения.
Подробнее — см. Инциденты.
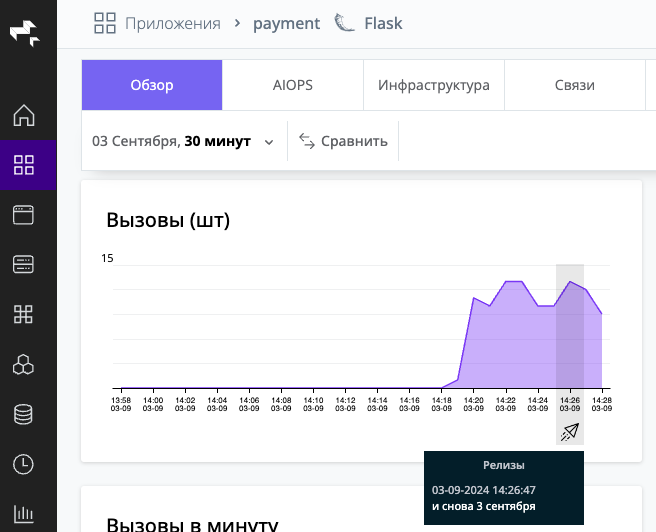
/api/annotations): он поддерживает не только релизы, но и любые события (деплои, изменения конфигурации, плановые работы, инциденты), точечные и интервальные маркеры и фильтрацию по тегам. Подробнее — в руководстве Маркеры событий (аннотации). Описанный ниже способ через marker.sh продолжает работать.Вы можете сообщать в Proto Observability Platform информацию о сделанном релизе из вашего CI/CD пайплайна. Для этого встройте в свой пайплайн вызов скрипта marker.sh со следующеми аргументами:
./marker.sh "адрес_бекенд_сервер" "название_релиза" "название сервиса (опционально)"
https://Например:
./marker.sh "proto-backend.fqdn" "и снова 3 сентября"
Содержимое marker.sh:
#!/bin/bash
PROTO_BACKEND_URL=${1}
PROTO_RELEASE_NAME=${2}
PROTO_SERVICE_NAME="${3}"
generate_post_data()
{
now=$(date +%s000)
if [ -z "${PROTO_SERVICE_NAME}" ]; then
cat <<EOF
[
{
"uuid": "${now}",
"name": "${PROTO_RELEASE_NAME}",
"source": {
"service": ""
},
"layer":"GENERAL",
"type": "RELEASE",
"message": "Релиз: ${PROTO_RELEASE_NAME} Сервис: Все",
"parameters": {},
"startTime": ${now},
"endTime": ${now}
}
]
EOF
else
cat <<EOF
[
{
"uuid": "${now}",
"name": "${PROTO_RELEASE_NAME}",
"source": {
"service": "${PROTO_SERVICE_NAME}"
},
"layer":"GENERAL",
"type": "RELEASE",
"message": "Релиз: ${PROTO_RELEASE_NAME}",
"parameters": {},
"startTime": ${now},
"endTime": ${now}
}
]
EOF
fi
}
# echo $(generate_post_data) | jq
curl -i -k \
-H "Accept: application/json" \
-H "Content-Type:application/json" \
-X POST --data "$(generate_post_data)" "https://${PROTO_BACKEND_URL}/v3/events"
Сквозной пример настройки оповещения в Proto Observability Platform: создать канал доставки, правило и политику маршрутизации и получить первое уведомление в Telegram.
Пошаговое руководство по настройке оповещений в Proto Observability Platform: создание каналов оповещений (email, Telegram, Webhook), политик маршрутизации и правил алертинга с описанием каждого поля формы.
Как смотреть сработавшие алерты в Proto Observability Platform: реальное время (Активные), история алертов с аналитикой и MTTR, лента событий.
Инциденты в Proto Observability Platform: автоматическая корреляция связанных алертов в единый инцидент, этапы жизненного цикла (ITIL), ИИ-сводка и ИИ-расследование первопричины, граф распространения и настройки инцидентов.
Справочник по написанию выражений для правил алертинга: доступные метрики сервисов и их лейблы, синтаксис фильтрации, примеры выражений на PromQL/MetricsQL и зарезервированные аннотации со ссылками на дашборды.
Автоматическое выявление аномалий в Proto Observability Platform: что такое базовая линия, какие метрики профилируются автоматически, какие встроенные правила алертинга по ним работают и как добавить собственные метрики в профилирование через конфигурацию.
Жизненный цикл алерта (pending/firing/resolved), чек-лист «почему уведомление не пришло» и формат уведомлений Proto Observability Platform — содержимое email и Telegram, payload вебхука.
Окна обслуживания в Proto Observability Platform: объявление регламентных работ, режимы «Сейчас», «Однократно» и «Регулярно», область действия, предпросмотр охвата, подавление оповещений и инцидентов, отображение на графиках.
Сквозной пример настройки многоуровневой эскалации оповещений в Proto Observability Platform на сценарии мониторинга ёмкости Ceph-кластера: уровни L1/L2/L3, маршрутизация по лейблам в разные каналы (email/Telegram/Webhook) и предиктивное правило исчерпания ёмкости.